GOES Satellite Hunt (Part 4 – Packet Demuxer)
 Written by
Lucas Teske
Written by
Lucas Teske
on
In the last chapter I showed how to get the frames from the demodulated bit stream. In this chapter I will show you how to parse these frames and get the packets that will on next chapter generate the files that GOES send. I will first add C code to the code I did in the last chapter to separated all the virtual channels by ID. But mainly this chapter will be done in python (just because its easier, I will eventually make a C code as well to do the stuff).
De-randomization of the data
One of the missing things on the last chapter was the frame data de-randomization. The data inside the frame (excluding the sync word) is randomized by a generator polynomial. This is done because of few things:
- Pseudo-random Symbols distribute better the energy in the spectrum
- Avoids “line-polarization” effect when sending a continuous stream of 1’s
- Better Clock Recovery due more changes in symbol polarity
CCSDS has a standard Polynomial as well, and the image below shows how to generate the pseudo-random bistream:

CCSDS Pseudo-random Bitstream Generator
The PN Generator polynomial (as shown in the LRIT spec) is x^8 + x^7 + x^5 + x^3 + 1. You can check several PN Sequence Generators on the internet, but since the repeating period of this PN is 255 bytes and we’re xor’ing with our bytestream I prefer to make a lookup table with all the 255 byte sequence and then just xor (instead generating and xor). Here is the 255 byte PN:
char pn[255] = {
0xff, 0x48, 0x0e, 0xc0, 0x9a, 0x0d, 0x70, 0xbc,
0x8e, 0x2c, 0x93, 0xad, 0xa7, 0xb7, 0x46, 0xce,
0x5a, 0x97, 0x7d, 0xcc, 0x32, 0xa2, 0xbf, 0x3e,
0x0a, 0x10, 0xf1, 0x88, 0x94, 0xcd, 0xea, 0xb1,
0xfe, 0x90, 0x1d, 0x81, 0x34, 0x1a, 0xe1, 0x79,
0x1c, 0x59, 0x27, 0x5b, 0x4f, 0x6e, 0x8d, 0x9c,
0xb5, 0x2e, 0xfb, 0x98, 0x65, 0x45, 0x7e, 0x7c,
0x14, 0x21, 0xe3, 0x11, 0x29, 0x9b, 0xd5, 0x63,
0xfd, 0x20, 0x3b, 0x02, 0x68, 0x35, 0xc2, 0xf2,
0x38, 0xb2, 0x4e, 0xb6, 0x9e, 0xdd, 0x1b, 0x39,
0x6a, 0x5d, 0xf7, 0x30, 0xca, 0x8a, 0xfc, 0xf8,
0x28, 0x43, 0xc6, 0x22, 0x53, 0x37, 0xaa, 0xc7,
0xfa, 0x40, 0x76, 0x04, 0xd0, 0x6b, 0x85, 0xe4,
0x71, 0x64, 0x9d, 0x6d, 0x3d, 0xba, 0x36, 0x72,
0xd4, 0xbb, 0xee, 0x61, 0x95, 0x15, 0xf9, 0xf0,
0x50, 0x87, 0x8c, 0x44, 0xa6, 0x6f, 0x55, 0x8f,
0xf4, 0x80, 0xec, 0x09, 0xa0, 0xd7, 0x0b, 0xc8,
0xe2, 0xc9, 0x3a, 0xda, 0x7b, 0x74, 0x6c, 0xe5,
0xa9, 0x77, 0xdc, 0xc3, 0x2a, 0x2b, 0xf3, 0xe0,
0xa1, 0x0f, 0x18, 0x89, 0x4c, 0xde, 0xab, 0x1f,
0xe9, 0x01, 0xd8, 0x13, 0x41, 0xae, 0x17, 0x91,
0xc5, 0x92, 0x75, 0xb4, 0xf6, 0xe8, 0xd9, 0xcb,
0x52, 0xef, 0xb9, 0x86, 0x54, 0x57, 0xe7, 0xc1,
0x42, 0x1e, 0x31, 0x12, 0x99, 0xbd, 0x56, 0x3f,
0xd2, 0x03, 0xb0, 0x26, 0x83, 0x5c, 0x2f, 0x23,
0x8b, 0x24, 0xeb, 0x69, 0xed, 0xd1, 0xb3, 0x96,
0xa5, 0xdf, 0x73, 0x0c, 0xa8, 0xaf, 0xcf, 0x82,
0x84, 0x3c, 0x62, 0x25, 0x33, 0x7a, 0xac, 0x7f,
0xa4, 0x07, 0x60, 0x4d, 0x06, 0xb8, 0x5e, 0x47,
0x16, 0x49, 0xd6, 0xd3, 0xdb, 0xa3, 0x67, 0x2d,
0x4b, 0xbe, 0xe6, 0x19, 0x51, 0x5f, 0x9f, 0x05,
0x08, 0x78, 0xc4, 0x4a, 0x66, 0xf5, 0x58
};
And for de-randomization just xor’it with the frame (excluding the 4 byte sync word):
for (int i=0; i<1020; i++) {
decodedData[i] ^= pn[i%255];
}
Now you should have the de-randomized frame.
Reed Solomon Error Correction
Other of the things that were missing on the last part is the Data Error Correction. We already did the Foward Error Correction (FEC, the viterbi), but we also can do Reed Solomon. Notice that Reed Solomon is completely optional if you have good SNR (that is better than 9dB and viterbi less than 50 BER) since ReedSolomon doesn’t alter the data. I prefer to use RS because I don’t have a perfect signal (although my average RS corrections are 0) and I want my packet data to be consistent. The RS doesn’t usually add to much overhead, so its not big deal to use. Also the libfec provides a RS algorithm for the CCSDS standard.
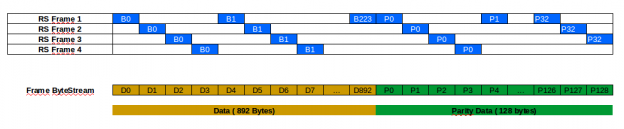
I will assume you have a uint8_t buffer with a frame data of 1020 bytes (that is, the data we got in the last chapter with the sync word excluded). The CCSDS standard RS uses 255,223 as the parameters. That means that each RS Frame has 255 bytes which 223 bytes are data and 32 bytes are parity. With this specs, we can correct any 16 bytes in our 223 byte of data. In our LRIT Frame we have 4 RS Frames, but the structure are not linear. Since the Viterbi uses a Trellis diagram, the error in Trellis path can generate a sequence of bad bytes in the stream. So if we had a linear sequence of RS Frames, we could corrupt a lot of bytes from one frame and lose one of the RS Frames (that means that we lose the entire LRIT frame). So the data is interleaved by byte. The image below shows how the data is spread over the lrit frame.

ReedSolomon Interleaving
For correcting the data, we need to de-interleave to generate the four RS Frames, run the RS algorithm and then interleave again to have the frame data. The [de]interleaving process are very simple. You can use these functions to do that:
#define PARITY_OFFSET 892
void deinterleaveRS(uint8_t *data, uint8_t *rsbuff, uint8_t pos, uint8_t I) {
// Copy data
for (int i=0; i<223; i++) {
rsbuff[i] = data[i*I + pos];
}
// Copy parity
for (int i=0; i<32; i++) {
rsbuff[i+223] = data[PARITY_OFFSET + i*I + pos];
}
}
void interleaveRS(uint8_t *idata, uint8_t *outbuff, uint8_t pos, uint8_t I) {
// Copy data
for (int i=0; i<223; i++) {
outbuff[i*I + pos] = idata[i];
}
// Copy parity - Not needed here, but I do.
for (int i=0; i<32; i++) {
outbuff[PARITY_OFFSET + i*I + pos] = idata[i+223];
}
}
For using it on LRIT frame we can do:
#define RSBLOCKS 4
int derrors[4] = { 0, 0, 0, 0 };
uint8_t rsWorkBuffer[255];
uint8_t rsCorrectedData[1020];
for (int i=0; i<RSBLOCKS; i++) {
deinterleaveRS(decodedData, rsWorkBuffer, i, RSBLOCKS);
derrors[i] = decode_rs_ccsds(rsWorkBuffer, NULL, 0, 0);
interleaveRS(rsWorkBuffer, rsCorrectedData, i, RSBLOCKS);
}
In the variable derrors we will have how many bytes it was corrected for each RS Frames. In rsCorrectedData we will have the error corrected output. The value -1 in derrors it means the data is corrupted beyond correction (or the parity is corrupted beyond correction). I usually drop the entire frame if all derrors are -1, but keep in mind that the corruption can happen in the parity only (we can have corrupted bytes in parity that will lead to -1 in error correction) so it would be wise to not do like I did. After that we will have the corrected LRIT Frame that is 892 bytes wide.
Virtual Channel Demuxer
Now we will demux the Virtual Channels. I current save all virtual channel payload (the 892 bytes) to a file called channel_ID.bin then I post process with a python script to separate the channel packets. Parsing the virtual channel header has also some advantages now that we can see if for some reason we skipped a frame of the channel, and also to discard the empty frames (I will talk about it later).

VCDU Header
Fields:
- Version Number – The Version of the Frame Data
- S/C ID – Satellite ID
- VC ID – Virtual Channel ID
- Counter – Packet Counter (relative to the channel)
- Replay Flag – Is 1 if the frame is being sent again.
- Spare – Not used.
Basically we will only use 2 values from the header: VCID and Counter.
uint32_t swapEndianess(uint32_t num) {
return \(\(num>>24)&0xff) | \(\(num<<8)&0xff0000) | \(\(num>>8)&0xff00) | \(\(num<<24)&0xff000000);
}
(...)
uint8_t vcid = (*(rsCorrectedData+1)) & 0x3F;
// Packet Counter from Packet
uint32_t counter = *((uint32_t *) (rsCorrectedData+2));
counter = swapEndianess(counter);
counter &= 0xFFFFFF00;
counter = counter >> 8;
I usually save the last counter value and compare with the current one to see if I lost any frame. Just be carefull that the counter value is per channel ID (VCID). I actually never got any VCID higher than 63, so I store the counter in a 256 int32_t array.
One last thing I do in the C code is to discard any frame that has 63 as VCID. The VCID 63 only contains Fill Packets, that is used for keeping the satellite signal continuous, even when not sending anything. The payload of the frame will always contain the same sequence (that can be sequence of 0, 1 or 01).
Packet Demuxer
Having our virtual channels demuxed for files channel_ID.bin, we can do the packet demuxer. I did the packet demuxer in python because of the easy of use. I plan to rewrite in C as well, but I will explain using python code.

Channel Data
Each channel Data can contain one or more packets. If the Channel contains and packet end and another start, the First Header Pointer (the 11 bits from the header) will contain the address for the first header inside the packet zone.
First thing we need to do is read one frame from a channel_ID.bin file, that is, 892 bytes (6 bytes header + 886 bytes data). We can safely ignore the 6 bytes header from VCDU now since we won’t have any usefulness for this part of the program. The spare 5 bits in the start we can ignore, and we should get the FHP value to know if we have a packet start in the current frame. If we don’t, and there is no pending packet to append data, we just ignore this frame and go to the next one. The FHP value will be 2047 (all 1’s) when the current frame only contains data related to a previous packet (no header). If the value is different than 2047 then we have a header. So let’s handle this:
data = data[6:] # Strip channel header
fhp = struct.unpack(">H", data[:2])[0] & 0x7FF
data = data[2:] # Strip M_PDU Header
#data is now TP_PDU
if not fhp == 2047: # Frame Contains a new Packet
# handle new header
So let’s talk first about handling a new packet. Here is the structure of a packet:

Packet Structure (CP_PDU)
We have a 6 byte header containing some useful info, and a user data that can vary from 1 byte to 8192 bytes. So this packet can span across several frames and we need to handle it. Also there is another tricky thing here: Even the packet header can be split across two frames (the 6 first bytes can be at two frames) so we need to handle that we might not have enough data to even check the packet header. I created a function called CreatePacket that receives a buffer parameter that can or not have enough data for creating a packet. It will return a tuple that contains the APID for the packet (or -1 if buffer doesn’t have at least 6 bytes) and a buffer that contains any unused data for the packet (for example if there was more than one packet in the buffer). We also have a function called ParseMSDU that will receive a buffer that contains at least 6 bytes and return a tuple with the MSDU (packet) header decomposed. There is also a SavePacket function that will receive the channelId (VCID) and a object to save the data to a packet file. I will talk about the SavePacket later.
import struct
SEQUENCE_FLAG_MAP = {
0: "Continued Segment",
1: "First Segment",
2: "Last Segment",
3: "Single Data"
}
pendingpackets = {}
def ParseMSDU(data):
o = struct.unpack(">H", data[:2])[0]
version = (o & 0xE000) >> 13
type = (o & 0x1000) >> 12
shf = (o & 0x800) >> 11
apid = (o & 0x7FF)
o = struct.unpack(">H", data[2:4])[0]
sequenceflag = (o & 0xC000) >> 14
packetnumber = (o & 0x3FFF)
packetlength = struct.unpack(">H", data[4:6])[0] -1
data = data[6:]
return version, type, shf, apid, sequenceflag, packetnumber, packetlength, data
def CreatePacket(data):
while True:
if len(data) < 6:
return -1, data
version, type, shf, apid, sequenceflag, packetnumber, packetlength, data = ParseMSDU(data)
pdata = data[:packetlength+2]
if apid != 2047:
pendingpackets[apid] = {
"data": pdata,
"version": version,
"type": type,
"apid": apid,
"sequenceflag": SEQUENCE_FLAG_MAP[sequenceflag],
"sequenceflag_int": sequenceflag,
"packetnumber": packetnumber,
"framesdropped": False,
"size": packetlength
}
print "- Creating packet %s Size: %s - %s" % (apid, packetlength, SEQUENCE_FLAG_MAP[sequenceflag])
else:
apid = -1
if not packetlength+2 == len(data) and packetlength+2 < len(data): # Multiple packets in buffer
SavePacket(sys.argv[1], pendingpackets[apid])
del pendingpackets[apid]
data = data[packetlength+2:]
apid = -1
print " Multiple packets in same buffer. Repeating."
else:
break
return apid, ""
With that we create a dictionary called pendingpackets that will store APID as the key, and another dictionary with the packet data, including a field called data that we will append data from other frames until we fill the whole packet. Back to our read function, we will have something like this:
...
if not fhp == 2047: # Frame Contains a new Packet
# Data was incomplete on last FHP and another packet starts here.
# basically we have a buffer with data, but without an active packet
# this can happen if the header was split between two frames
if lastAPID == -1 and len(buff) > 0:
print " Data was incomplete from last FHP. Parsing packet now"
if fhp > 0:
# If our First Header Pointer is bigger than 0, we still have
# some data to add.
buff += data[:fhp]
lastAPID, data = CreatePacket(buff)
if lastAPID == -1:
buff = data
else:
buff = ""
if not lastAPID == -1: # We are finishing another packet
if fhp > 0: # Append the data to the last packet
pendingpackets[lastAPID]["data"] += data[:fhp]
# Since we have a FHP here, the packet has ended.
SavePacket(sys.argv[1], pendingpackets[lastAPID])
del pendingpackets[lastAPID] # Erase the last packet data
lastAPID = -1
# Try to create a new packet
buff += data[fhp:]
lastAPID, data = CreatePacket(buff)
if lastAPID == -1:
buff = data
else:
buff = ""
This should handle all frames that has a new header. But maybe the packet is so big that we got frames without any header (continuation packets). In this case the FHP will be 2047, and basically we have three things that can lead to that:
- The header was split between last frame end, and the current frame. FHP will be 2047 and after we append to our buffer we will have a full header to start a packet
- We just need to append the data to last packet.
- We lost some frame (or we just started) and we got a continuation packet. So we drop it.
...
else:
if len(buff) > 0 and lastAPID == -1: # Split Header
print " Data was incomplete from last FHP. Parsing packet now"
buff += data
lastAPID, data = CreatePacket(buff)
if lastAPID == -1:
buff = data
else:
buff = ""
elif len(buff)> 0:
# This shouldn't happen, but I put a warn here if it does
print " PROBLEM!"
elif lastAPID == -1:
# We don't have any pending packets, and we received
# a continuation packet, so we drop.
pass
else:
# We have a last packet, so we append the data.
print " Appending %s bytes to %s" % (lastAPID, len(data))
pendingpackets[lastAPID]["data"] += data
Now let’s talk about the SavePacket function. I will describe some of the stuff here, but there will be also something described on the next chapter. Since the packet data can be compressed, we will need to check if the data is compressed, and if it is, we need to decompress. In this part we will not handle the decompression or the file assembler (that will need decompression).
Saving the Raw Packet
Now that we have the handler for the demuxing, we will implement the function SavePacket. It will receive two arguments, the channel id and a packetdict. The channel id will be used for saving the packets in the correct folder (separating them from other channel packets). We may have also a Fill Packet here, that has an APID of 2047. We should drop the data if the apid is 2047. Usually the fill packets are only used to increase the likely hood of the header of packet starts on the start of channel data. So it “fills” the channel data to get the header in the next packet. It does not happen very often though.
In the last step we assembled a packet dict with this structure:
{
"data": pdata,
"version": version,
"type": type,
"apid": apid,
"sequenceflag": SEQUENCE_FLAG_MAP[sequenceflag],
"sequenceflag_int": sequenceflag,
"packetnumber": packetnumber,
"framesdropped": False,
"size": packetlength
}
The data field have the data we need to save, the type says the type of packet (and also if its compressed), the sequenceflag says if the packet is:
- ** => Continued Segment, if this packet belongs to a file that has been already started.
- 1 => First Segment, if this packet contains the start of the file
- 2 => Last Segment, if this packet contains the end of the file
- 3 => Single Data, if this packet contains the whole file
It also contains a packetnumber that we can use to check if we skip any packet (or lose).
The size parameter is the length of data field – 2 bytes. The two last bytes is the CRC of the packet. The CCSDS only specify the polynomial for the CRC, CRC-CCITT standard. I made a very small function based on a few C functions I found over the internet:
def CalcCRC(data):
lsb = 0xFF
msb = 0xFF
for c in data:
x = ord(c) ^ msb
x ^= (x >> 4)
msb = (lsb ^ (x >> 3) ^ (x << 4)) & 255
lsb = (x ^ (x << 5)) & 255
return (msb << 8) + lsb
def CheckCRC(data, crc):
c = CalcCRC(data)
if not c == crc:
print " Expected: %s Found %s" %(hex(crc), hex(c))
return c == crc
On SavePacket function we should check the CRC to see if any data was corrupted or if we did any mistake. So we just check the CRC and then save the packet to a file (at least for now):
EXPORTCORRUPT = False
def SavePacket(channelid, packet):
global totalCRCErrors
global totalSavedPackets
global tsize
global isCompressed
global pixels
global startnum
global endnum
try:
os.mkdir("channels/%s" %channelid)
except:
pass
if packet["apid"] == 2047:
print " Fill Packet. Skipping"
return
datasize = len(packet["data"])
if not datasize - 2 == packet["size"]: # CRC is the latest 2 bytes of the payload
print " WARNING: Packet Size does not match! Expected %s Found: %s" %(packet["size"], len(packet["data"]))
if datasize - 2 > packet["size"]:
datasize = packet["size"] + 2
print " WARNING: Trimming data to %s" % datasize
data = packet["data"][:datasize-2]
if packet["sequenceflag_int"] == 1:
print "Starting packet %s_%s_%s.lrit" % (packet["apid"], packet["version"], packet["packetnumber"])
startnum = packet["packetnumber"]
elif packet["sequenceflag_int"] == 2:
print "Ending packet %s_%s_%s.lrit" % (packet["apid"], packet["version"], packet["packetnumber"])
endnum = packet["packetnumber"]
if startnum == -1:
print "Orphan Packet. Dropping"
return
elif packet["sequenceflag_int"] != 3 and startnum == -1:
print "Orphan Packet. Dropping."
return
if packet["framesdropped"]:
print " WARNING: Some frames has been droped for this packet."
filename = "channels/%s/%s_%s_%s.lrit" % (channelid, packet["apid"], packet["version"], packet["packetnumber"])
print "- Saving packet to %s" %filename
crc = packet["data"][datasize-2:datasize]
if len(crc) == 2:
crc = struct.unpack(">H", crc)[0]
crc = CheckCRC(data, crc)
else:
crc = False
if not crc:
print " WARNING: CRC does not match!"
totalCRCErrors += 1
if crc or (EXPORTCORRUPT and not crc):
f = open(filename, "wb")
f.write(data)
f.close()
totalSavedPackets += 1
else:
print " Corrupted frame, skipping..."
With that you should be able to see a lot of files being out of your channel, each one being a packet. If you get the first packet (with the sequenceflag = 1), you will also have the Transport Layer header that contains the decompressed file size, and file number. We will handle the decompression and lrit file composition in next chapter. You can check the final code here: https://github.com/racerxdl/open-satellite-project/blob/master/GOES/standalone/channeldecoder.py