em
File Header Processing
The LRIT File has several headers. The first one is from the transport layer that says what is the file number and what is the total decompressed size. i usually ignore this data because its only used for validation of the finished file. This header has 10 bytes.
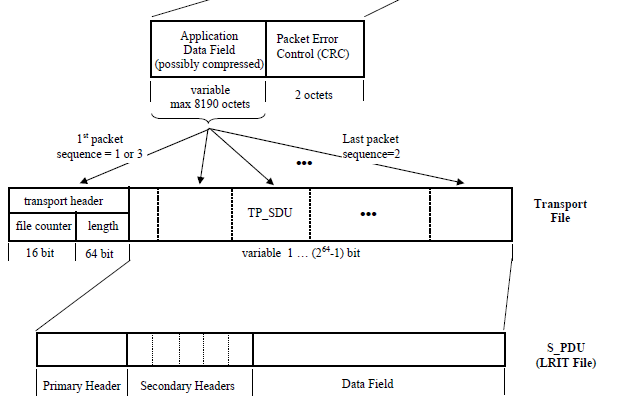
Discarding the first 10 bytes (2 bytes for file counter and 8 bytes for the length), you will have the Primary Header. The primary header has basically just the size of the LRIT File header. We will need to parse all the headers (including the secondary) in order to find if the continuation packets will be compressed and if they are, what are the parameters to decompress (yes, they can change). I created a packetmanager.py script to export few helper functions to parse the header inside channeldecode.py. There are several header types with different lengths, but they do have two parameters in common:
- Type – 1 byte (uint8_t)
- Size – 2 byte (uint16_t)
So what I usually do, is to grab the first 3 bytes of a header, check the size (the size includes these 3 bytes) and then fetch more size – 3 bytes to the buffer. With this buffer I pass to another function that will parse the header data and return a object with their parameters. This is my parseHeader function:
def parseHeader(type, data):
if type == 0:
filetypecode, headerlength, datalength = struct.unpack(">BIQ", data)
return {"type":type, "filetypecode":filetypecode, "headerlength":headerlength, "datalength":datalength}
elif type == 1:
bitsperpixel, columns, lines, compression = struct.unpack(">BHHB", data)
return {"type":type, "bitsperpixel":bitsperpixel, "columns":columns, "lines":lines, "compression":compression}
elif type == 2:
projname, cfac, lfac, coff, loff = struct.unpack(">32sIIII", data)
return {"type":type, "projname":projname, "cfac":cfac, "lfac":lfac, "coff":coff, "loff":loff}
elif type == 3:
return {"type":type, "data":data}
elif type == 4:
return {"type":type, "filename":data}
elif type == 5:
days, ms = struct.unpack(">HI", data[1:])
return {"type":type, "days":days, "ms":ms}
elif type == 6:
return {"type":type, "data":data}
elif type == 7:
return {"type":type, "data":data}
elif type == 128:
imageid, sequence, startcol, startline, maxseg, maxcol, maxrow = struct.unpack(">7H", data)
return {"type":type, "imageid":imageid, "sequence":sequence, "startcol":startcol, "startline":startline, "maxseg":maxseg, "maxcol":maxcol, "maxrow":maxrow}
elif type == 129:
signature, productId, productSubId, parameter, compression = struct.unpack(">4sHHHB", data)
return {"type":type, "signature":signature, "productId":productId, "productSubId":productSubId, "parameter":parameter, "compression":compression}
elif type == 130:
return {"type":type, "data":data}
elif type == 131:
flags, pixel, line = struct.unpack(">HBB", data)
return {"type":type, "flags":flags, "pixel":pixel, "line":line}
elif type == 132:
return {"type":type, "data": data}
else:
return {"type":type}
And since we should read all headers, here is the getHeaderData function:
def getHeaderData(data):
headers = []
while len(data) > 0:
type = ord(data[0])
size = struct.unpack(">H", data[1:3])[0]
o = data[3:size]
data = data[size:]
td = parseHeader(type, o)
headers.append(td)
if td["type"] == 0:
data = data[:td["headerlength"]-size]
return headers
With that, we have enough stuff for using in our channeldecoder.py and know if the file is compressed. Basically we can do a simple import packetmanager and use the packetmanager.py functions.
More details about LRIT File Headers is described at LRIT Header Description